New PROMICON-supported paper investigates deep learning techniques in the context of hybrid modelling
Hybrid semiparametric systems that combine shallow neural networks with First Principles have been widely used for bioprocess modelling. In light of that, a new PROMICON-supported paper, recently published in the Computers & Chemical Engineering Journal, was specifically interested in advancing the assessment of the general bioreactor hybrid model and introducing some recent deep learning techniques.
In the newly published study ‘A general deep hybrid model for bioreactor systems: Combining first principles with deep neural networks’, the researchers, amongst whom project partners from Nova University Lisbon, investigated the effect of increasing the depth of the neural network resorting to different training approaches. The deep learning techniques, namely the adaptive moment estimation method (ADAM), stochastic regularisation and depth-dependent weights initialisation were evaluated in a hybrid modelling context. The paper thoroughly describes the method development, validation and verification, as well as the materials and methods used in the process.
The study reports that the key conclusion to be taken is that there is a clear advantage of adopting hybrid deep models both in terms of predictive power and in terms of computational cost in relation to the shallow hybrid case. All in all, the results point to a systematic generalisation improvement of deep hybrid models over its shallow counterpart.
Read the full paper here.
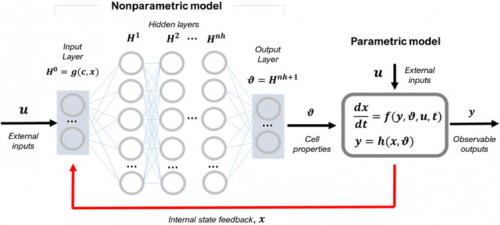
Photo: Schematic representation of the general deep hybrid model for bioreactor systems. The model is dynamic in nature with state vector, x, and observable outputs y. The model has a parametric component (functions f(.) and h(.)) with fixed mathematical structure determined by First Principles (typically material/energy balance equations). Some cellular properties are modelled by a deep feedforward neural network with multiple hidden layers as function of the process state, x, and external inputs, u. The deep neural network is a nonparametric model component with loose structure that must be identified from process data given the absence of explanatory mechanisms for that particular part of the model.